Social & Information Networks
Link prediction is the task of predicting previously unobserved relationships between entities. There are many exciting applications of this particular area of network science. Most research in the area of link prediction has been restricted to scoring based on a single measure within network topologies. Our work is developing a powerful new measure and placing existing measures in the context of a machine learning task. We are also casting the problem as a high-class imbalance task.
Click the title of the project to view the description.
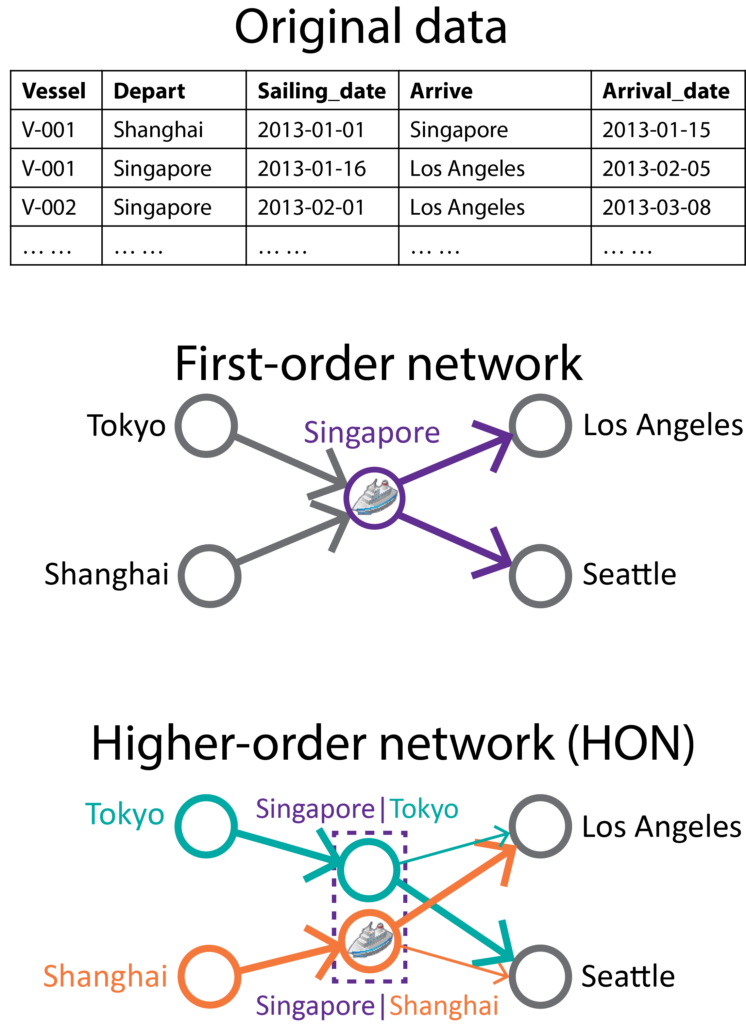
Representing complex systems as graphs: the higher-order network approach
Graphs, or networks, are expressive and flexible structures for representing interactions in complex systems. For example, given the trajectories of ships, a global shipping network can be constructed by assigning port-to-port traffic as edge weights. However, conventional first-order networks only capture pairwise (i.e., first-order Markov) traffic between ports, disregarding the fact that ship movements can depend on multiple previous steps. The loss of information during graph construction can lead to suboptimal results for downstream learning tasks. Higher-order networks (HONs) remedies this problem by creating conditional nodes, which embed higher-order dependencies in the graph. For more details, you can visit the seminal project website, read about recent applications of HONs for anomaly detection, analysis of type 2 diabetes comorbidities, and graph neural networks; or use our Python code to create your own higher-order network.
Encoding Real-World Heterogeneous Graphs to Improve Food Services
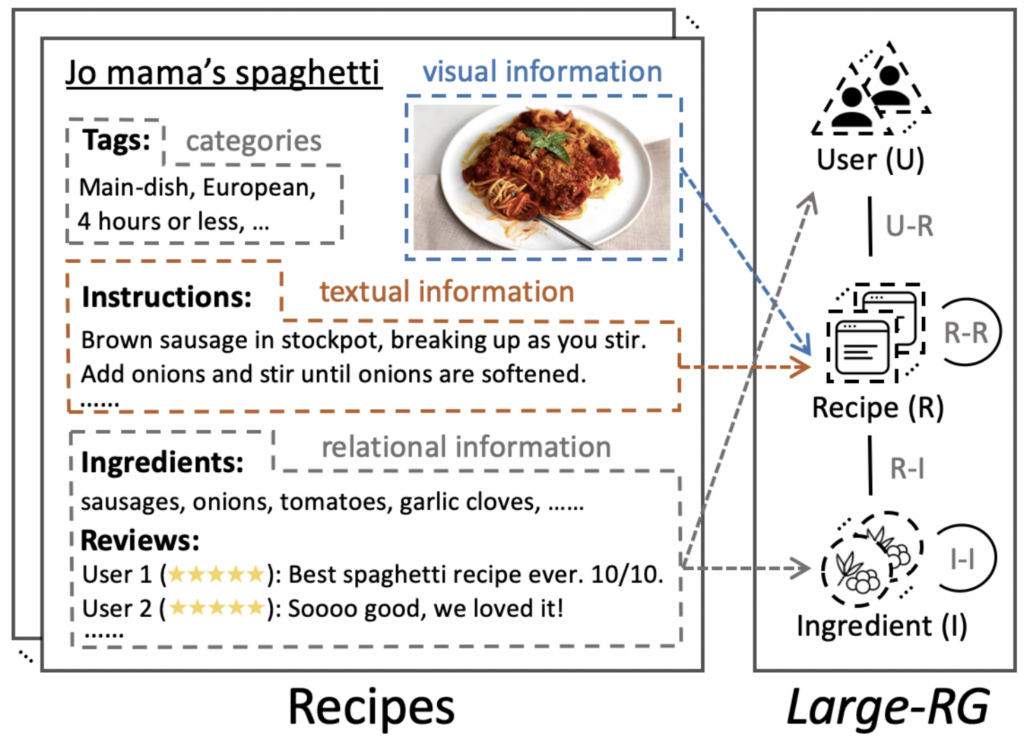
Heterogeneous graphs are ubiquitous in the real world with their ability to model heterogeneous relationships among different types of nodes, such as social graphs and food graphs. In particular, heterogeneous graphs have shown great promise in the field of recipe representation learning and recommendation. In this context, a heterogeneous recipe graph is a graph structure that captures the relationships between users, recipes, and ingredients. For example, a user node can be connected to a recipe node if the user has interacted with that recipe (e.g., liked, commented, or saved). Similarly, a recipe node can be connected to an ingredient node if the recipe contains that ingredient. By building a heterogeneous recipe graph, we can learn a comprehensive representation of recipes. This representation can then be used to recommend recipes to users based on their preferences and past interactions. In this way, heterogeneous graph-based approaches offer a powerful tool for improving recipe recommendation systems and enhancing the overall user experience.
Influence Drives the Emergence and Growth of Social Networks
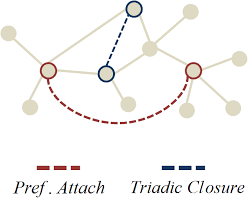
Social influence has been a widely accepted phenomenon in social networks for decades. This includes influence maximization, influence selection and quantification, and influence validation. Different from existing work, our research focuses on the effects of social influence on the evolution of social networks, aiming to answer that whether social influence is a strong force shaping the network dynamics. The problem is explored from both microscopic and macroscopic perspectives. In microscopic level, we try to answer the question that whether the model derived from social influence propagation mechanism can yield high precision in the link prediction problem. While from macroscopic perspective, we are also interested to know whether the model hypothesized from social influence spreading is able to explain popular scaling-laws in social networks. Our objective is to unveil the significant factors with a great degree of precision than has heretofore been possible, and shed new light on networks evolution.
Longitudinal Analysis and Modeling of Large-Scale Social Networks

The growth in information technology systems is generating new sources of data on human behavior that are only now beginning to be analyzed. Digital communications systems log communication events and therefore contain valuable information on usage patterns that can be used to map social networks and analyze human behaviors within them. The availability of this data of over millions of individuals provides the potential to induce transformative changes in the way we analyze and understand human behavior. The data generated by digital communication technologies has five key traits that have the potential to transform the way researchers study social networks: 1) quality of statistics (the data comes from millions of users), 2) purely observational (non-obtrusive measurement), 3) complete network data (not just information on the ego networks of a sample of people) 4) longitudinal (spanning several years), and 5) spatial information (e.g., cell-phones can be geographically located). Data of such extent and longitudinal character brings with it novel challenges which can only be tackled by a well orchestrated multidisciplinary approach involving network social science, physics methods developed for large-scale interacting particle systems, mathematical statistics and data analysis, and computer science methods of data mining, community detection algorithms and agent-based modeling.
Understanding Peace Processes through Social Media

Colombia’s final peace agreement was a culmination of a decade-long peace process that outlines significant social, political and economic reforms to end the longest fought armed conflict in the Western Hemisphere. Peace processes are complex, protracted, contentious and dynamic systems which involve significant bargaining and compromising among various societal and political stakeholders. Social media yields tremendous power in peace processes as a tool for dialogue, debate, organization, and mobilization thereby adding more complexity by opening the peace process to public influence. Various indicators such as renunciation of violence during talks, establishing a negotiating agenda and its sequences, public support, and external guarantees can enable us to better understand peace process dynamics and predicting their outcomes. In this paper, we study two important indicators: inter-group polarization and public sentiment towards the Colombian peace process. We present a detailed linguistic analysis to detect inter-group polarization and understand differences in signals emerging from polarized groups. We also present a predictive model which leverages tweet-based, content-based and user-based features to predict public sentiment towards the Colombian peace process as observed through social media.
Connecting the Dots to Infer Followers’ Topical Interest on Twitter
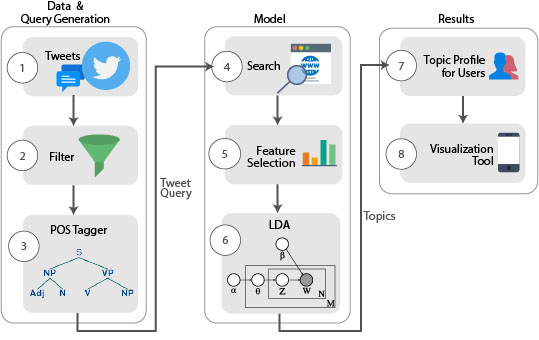
Twitter provides a platform for information sharing and diffusion, and has quickly emerged as a mechanism for organizations to engage with their consumers. A driving factor for engagement is providing relevant and timely content to users. We posit that the engagement via tweets offers a good potential to discover user interests and leverage that information to target specific content of interest. To that end, we have developed a framework that analyzes tweets to identify the interests of current followers and leverages topic models to deliver a personalized topic profile for each user. We validated our framework by partnering up with a local media company and analyzing the content gap between them and their followers. We also developed a mobile application that incorporates the proposed framework.
Language Models
Large language models (LLMs) are neural networks capable of processing and understanding human language that can be used to tackle many complex problems. While the internet has made it possible to collect large amounts of text data that can be used to train and test large language models, unexplored venues and unsolved issues still remain. Our projects in this space focus on efficient information extraction from informal written conversations, applications of LLMs in novel domains, and improving LLMs to be more robust do data issues typically associated with text data.
Click the title of the project to view the description.
Determination of helpful or correct comments in an online forum
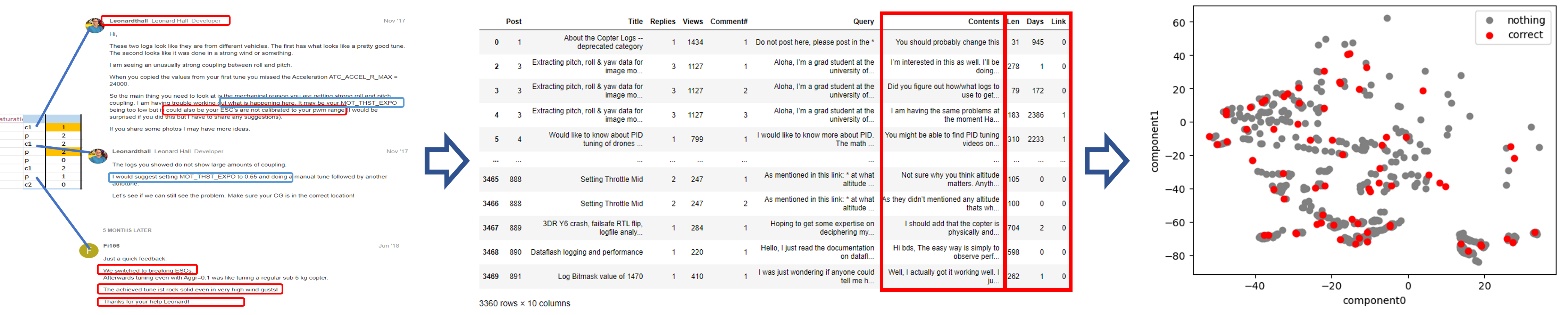
We can retrieve valuable information from an online forum discussion. There are complex relationships between individual users and also between each comment. As we all know, there are many comments for each thread in a forum, which can be either helpful or not. We, as humans, intuitively distinguish helpful comments from others. However, this is not always the case. If someone wants some information from a specific domain of knowledge, they wouldn’t easily be able to find those helpful comments unless they are familiar with the area. Because of these difficulties, we might miss some valuable but unstructured and hidden information. However, this research can help us get this information. As a part of the NASA project, this research is now exploring ArduPilot which is an online forum about Unmanned Aircraft Systems (UASs). We use text data which is the contents of each comment, the metadata of each comment such as the length of a comment, and the user stat information. We are experimenting with diverse language embedding models, features, and algorithms for classification. For the next step, we will tackle determining the correct comments even though the existence of the comments is a very rare case. For the threads that contain the correct comment, we can determine the answer to a thread and conclude the discussion.
LLMs and Evidence Synthesis
When it comes to working with scientific papers, defining interventions and their outcomes can be a tricky task even for a human. This process is often hampered by a lack of reliable and accurate data, which can be attributed to the complex manual labeling process involved. However, with the help of semi-automatic data cleaning and binary/ multi-label classification techniques, we can extract meaningful information from large volumes of textual data. To achieve this, we are developing a large language model that can accurately classify and label data, using active learning techniques to continually improve its performance over time. By doing so, we hope to overcome the challenges of accurately recognizing interventions and outcomes mentioned in text, and extract relevant information from reports efficiently. With this approach, we aim to make the process of data cleaning and labeling less cumbersome and more effective.
LLMs and Imbalanced Data
Another project deals with the fact that despite millions of person-hours of research, imbalanced data is still a challenge for supervised learning. This problem affects large language models as well. This can lead to significant biases in these models that play an increasingly larger role in our society. At the same time, the proportion of the target class in text datasets can be extremely low, and this remains in many important datasets. For tabular data, oversampling techniques such as SMOTE are used. However, using this type of oversampling on texts is a hard task, as conventional notions of distance do not apply to text. Our work focuses on developing novel ways to train large language models on a variety of tasks to make them more robust to class imbalance. In our research, we are trying to combine both cost-based approaches that take class distribution into account during LLM training with modern resampling techniques. With these techniques, we try to improve the applicability of LLMs to problems where balanced text datasets are not available.